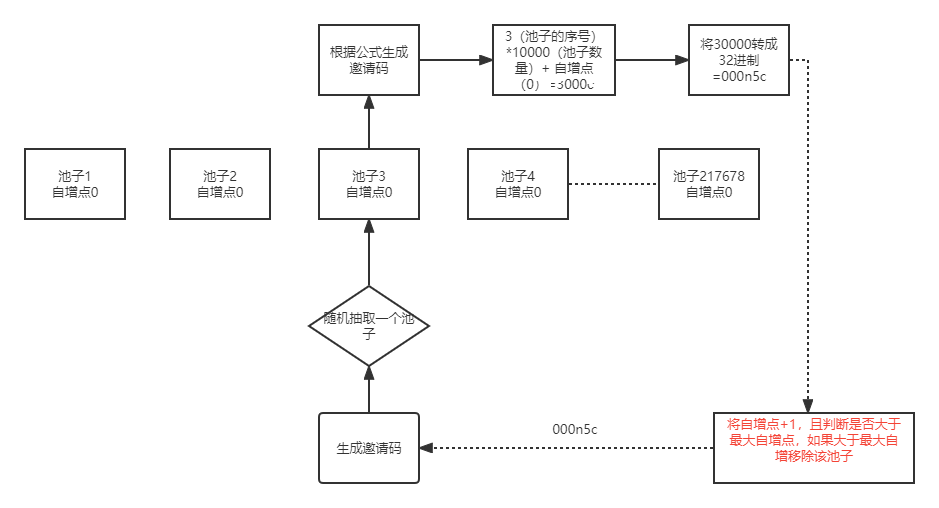
什么是ffmepg?按维基百科的说法:FFmpeg 是一个开放源代码的自由软件,可以执行音频和视频多种格式的录影、转换、串流功能,包含了libavcodec——这是一个用于多个项目中音频和视频的解码器库,以及libavformat——一个音频与视频格式转换库
视频压缩,说白了就是要让视频的大小降低,同时尽量不降低质量。如果为了降低大小,画质惨不忍睹这也是不能接受的。接下来就让我们了解一下与视频画质以及大小相关的一些要素
1.视频相关名称解释
帧率:FPS(frame per second 每秒钟要多少帧画面) GOP(表示多少秒一个I帧)
码率:编码器每秒编出的数据大小,单位是kbps,比如800kbps代表编码器每秒产生800kb(或100KB)的数据。
分辨率:单位英寸中所包含的像素点数;
VGA:Video Graphics Array(视频图像分辨率)
2.如何让视频变小
想要让视频变小,其中的关键因素是码率以及分辨率。帧率的话大部分情况下较小影响。如果非特殊的一些业务需求,帧率一般不变即可。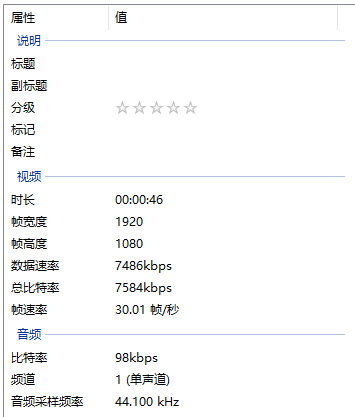
这里有一条公式:码率=文件实际大小(kb) X 8/时长(s),由此我们可以看出来,码率越大视频所占空间大小就越多。
按照这样子的说法,我们肯定会想那我把码率调到最低岂不是美滋滋。确实视频的空间大小会急速下降,但是你打开视频肯定会惊呆,画质十分感人根本就看不清。你想一下,码率其实就是编码器每秒编出的数据大小,如果你的码率很低,编码器每秒传输的数据很少,编码器就会用一些奇奇怪怪的马赛克来补充你视频的画面,这就是解释了为什么视频看起来会很模糊还会有一层朦胧的感觉。
在码率一定的情况下,分辨率与清晰度成反比关系:分辨率越高,图像越不清晰,分辨率越低,图像越清晰。 在分辨率一定的情况下,码率与清晰度成正比关系,码率越高,图像越清晰;码率越低,图像越不清晰
还有一个需要注意的地方:码率跟分辨率需要平衡。假设分辨率很高,码率比较低,这样子的画质也会有一定的影响的。720p较高的码率跟1080p较低的码率,720p的视频画质可能会看起来更加清晰。
3.实战
了解影响视频空间大小的因素后,我们就可以开始对视频的参数进行调整压缩了。为了快速开发,我采用了php的laravel框架以及PHP-FFMpeg 组件进行开发(因为其中涉及到一些云服务商以及业务的处理)。需要依赖ffmpeg,这里就不对ffmpeg安装进行过多讲解,google搜索很多方法。以下是主要的核心压缩代码,已屏蔽了业务相关的代码
//创建ffmpeg驱动$driver = FFMpeg::create(['ffmpeg.binaries' => 'ffmpeg_binaries','ffprobe.binaries' => 'ffprobe_binaries','timeout' => '', // The timeout for the underlying process'ffmpeg.threads' => '', // The number of threads that FFMpeg should use,]);//打开视频$video = $driver->open($filePath)//这里是拿ffprobe的驱动获取视频的信息$streams = $driver->getFFProbe() ->streams($filePath) ->videos() ->first();//拿到对应的分辨率$width = $streams->get('width');$height = $streams->get('height');//压缩到最低分辨率,这里取最短边$minResolution = 720;//这里是设置的动态码率(最大为1200k)、分辨率设置为720p,如果最短边低于720则不处理$addParams = ["-maxrate", ["1200k"], "-bufsize", "5000k"]; if ($width > $height) { //最短边为高 if ($height > $minResolution) { $addParams = array_merge($addParams, ["-vf", sprintf("scale=-2:%d", $minResolution)]); }} else {//最短边为宽 if ($width > $minResolution) { $addParams = array_merge($addParams, ["-vf", sprintf("scale=%d:-2", $minResolution)]); }}//这里设置了264编码$format = new X264();//因为默认设置了码率是1000k所以这里设置为null$format->setKiloBitrate(null);//这里了一些额外的参数进行压缩$format->setAdditionalParameters($addParams); $video->save($format, $tempFile);以上的php代码其实就是在做一件事,组装ffmpeg命令最终输出文件,至于参数怎么设置可以根据你业务的需要进行调整。这里在vf参数的scale为啥要输入-2呢,输入-1或者-2都是动态进行调整,这样就不会导致你的视频因为调整视频分辨率而变形。输入-1有可能刚好计算出来的长度或者宽度不能够被2整除就会报错。
ffmpeg -y -i 输入视频文件路径 -threads 5 -vcodec libx264 -acodec aac -b:a 128k -maxrate 1200k -bufsize 5000k -vf scale=720:-2 输出视频文件路径]]>以上就是本次我对于视频压缩的一些做法以及见解,如何做好最优解是需要不断的发现问题并解决问题的。现在的压缩效果大体上能满足业务的需求,毕竟代码说到底就是在为业务服务。只要能满足业务需求,并且后期有足够的扩展空间就算是好的解决方案。